Multiple correspondence analysis (MCA) is a statistical technique for nominal data (categorical data without overlaps) that represents the data as points in low-dimensions. It is a counterpart to principle component analysis and an extension to correspondence analysis.
Correspondence Analysis
Correspondence analysis (CA) provides a means of displaying or summarizing a set of categorical data in two-dimensional graphical form. It is typically applied to a contingency table of a pair of nominal variables where each cell is a count or a zero value. An example of a contingency table is given below:
| Right-handed | Left-Handed | Total | |
|---|---|---|---|
| Male | 43 | 9 | 52 |
| Female | 44 | 4 | 48 |
| Total | 87 | 13 | 100 |
The first step before any computation is to transform the values in the matrix . We start by computing a set of weights (called masses) for rows and columns:
where is the all-ones column vector and
We then construct diagonal matrices:
We then compute the matrix , called the matrix of standardized residuals, by
where is the outer product.
We then perform singular value decomposition on to get
where and are the left and right unitary singular vectors of and is the diagonal matrix of singular values . is of dimension , is and is of dimension where .
We define the total inertia of the data table by
We want to transform the singular vectors to coordinates, forming the principal coordinates, while preserving the -distances between rows or columns. For rows we use
and for columns we use
Example
Consider the following contingency table, :
| Tasty | Aesthetic | Economic | |
|---|---|---|---|
| Butterbeer | 5 | 7 | 2 |
| Squishee | 18 | 46 | 20 |
| Slurm | 19 | 29 | 39 |
| Fizzy | 12 | 40 | 49 |
| Brawndo | 3 | 7 | 16 |
Adding up the cells gives us that . Resulting in a observed proportions table, , of
| Tasty | Aesthetic | Economic | |
|---|---|---|---|
| Butterbeer | 0.016 | 0.022 | 0.006 |
| Squishee | 0.058 | 0.147 | 0.064 |
| Slurm | 0.061 | 0.093 | 0.125 |
| Fizzy | 0.038 | 0.128 | 0.157 |
| Brawndo | 0.01 | 0.022 | 0.051 |
| We get a row masses of |
and column masses of
Computing the SVD of results in the following data:
- Singular values ():
| 1st dim | 2nd dim | 3rd dim |
|---|---|---|
| 2.65e-01 | 1.14e-01 | 4.21e-17 |
- Left singular values ():
| 1st dim | 2nd dim | 3rd dim | |
|---|---|---|---|
| Butterbeer | -0.439 | -0.424 | -0.326 |
| Squishee | -0.651 | 0.355 | 0.029 |
| Slurm | 0.16 | -0.672 | -0.362 |
| Fizzy | 0.371 | 0.488 | -0.747 |
| Brawndo | 0.466 | -0.059 | 0.451 |
- Right singular values ():
| 1st dim | 2nd dim | 3rd dim | |
|---|---|---|---|
| Tasty | -0.41 | -0.806 | 0.427 |
| Aesthetic | -0.489 | 0.59 | 0.643 |
| Economic | 0.77 | -0.055 | 0.635 |
| We can then compute the row principle coordinates (): |
| 1st dim | 2nd dim | 3rd dim | |
|---|---|---|---|
| Butterbeer | -5.49e-01 | -2.271e-01 | -1.009e-16 |
| Squishee | -3.331e-01 | 7.768e-02 | 3.673e-18 |
| Slurm | 8.05e-02 | -1.446e-01 | -4.494e-17 |
| Fizzy | 1.73e-01 | 9.748e-02 | -8.609e-17 |
| Brawndo | 4.305e-01 | -2.352e-02 | 1.024e-16 |
| and the column principle coordinates (): |
| 1st dim | 2nd dim | 3rd dim | |
|---|---|---|---|
| Tasty | -2.543e-01 | -2.14e-01 | 6.555e-17 |
| Aesthetic | -2.016e-01 | 1.041e-01 | 6.555e-17 |
| Economic | 3.215e-01 | -9.751e-03 | 6.555e-17 |
Finally to visualize the results, we plot both coordinates with the first dimension on the -axis and the second dimension on the -axis:
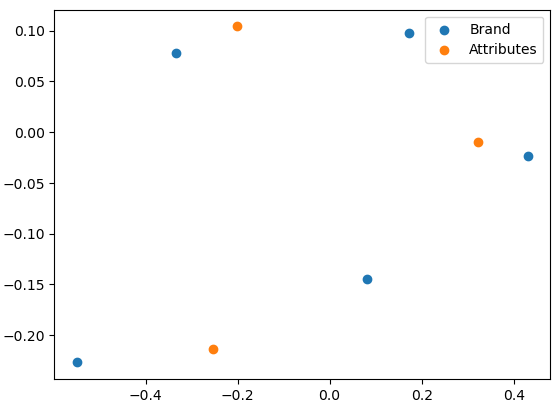
Multiple Correspondence Analysis
MCA is performed by applying the CA algorithm to an indicator matrix (aka complete disjunctive table, see One-Hot Encoding). MCA only works on categorical data; any quantitative data (e.g. age, weight, height, etc) must be turned into categories through a method such as statistical quantiles.
Once the data set is only categorical, we construct the indicator matrix/table . As a result, if there are observations and categorical variables where is the number of categories for the -th variable, then is an matrix with all coefficients being 0 or 1 where .
We define where is the sum of all entries of . We construct two vectors:
i.e., is the sums along the rows of and is the sums along the columns of . We then find the singular value decomposition of
where and . The SVD of gives us unitary matrices and diagonal matrix such that . Then like before, we construct the row principle coordinates by
and the column principle coordinates by
Interpreting Correspondence Plots
Correspondence analysis is about the relativistic relations. A correspondence analysis won’t show which rows/column have the maximum, instead it will tell you what categories had the most.
The distance from the origin is a measure of how discriminating a column is. Variables close to the origin typically have less distinct values.
Columns that are close together (ensure the plots aspect ratio is set to 1) is an indication of similarity between them. To compare the relationship between rows and columns you have to instead look for small angles between the line connecting them and the line to the origin.