Support vector machines are supervised machine learning models that analyze data for classification and regression analysis. Suppose the data is split into two classes, our goal is decide whether a new point belongs in class A or class B. Using a linear classifier, we take a data set in and separate the data with a -dimensional hyperplane.

There may be several hyperplanes that separate the data. We choose the hyperplane that maximizes the separation of the data. Such a hyperplane is called the maximum-margin hyperplane.
It is often the case that the data set is not linearly separable. To circumnavigate this issue, we map the data into a higher dimensional space where the data is separable. Such a mapping is defined such that the dot products of vectors may be computed easily in terms of the original space. We do this by defining them via a kernel function . In the higher dimension, the hyperplane is then the set of points whose dot product with a vector in that space is constant. We can view the hyperplane as a linear combination of images of feature vectors . Under this, the points in the feature space that get mapped into the hyperplane are given by the relation
The sum of kernels above can be used to measure the relative nearness of a test point to the data points originating in one of the discriminated sets.
Linear SVM
Given a set of training dataset of points where indicates the class belongs to and each . Our goal is to find the maximum-margin hyperplane that divides the vectors into groups ( and ) and so that the nearest point from either group is maximized.
Recall that any hyperplane can be written in the form
where is the normal vector to the hyperplane. The term determines the offset of the hyperplane from the origin along .
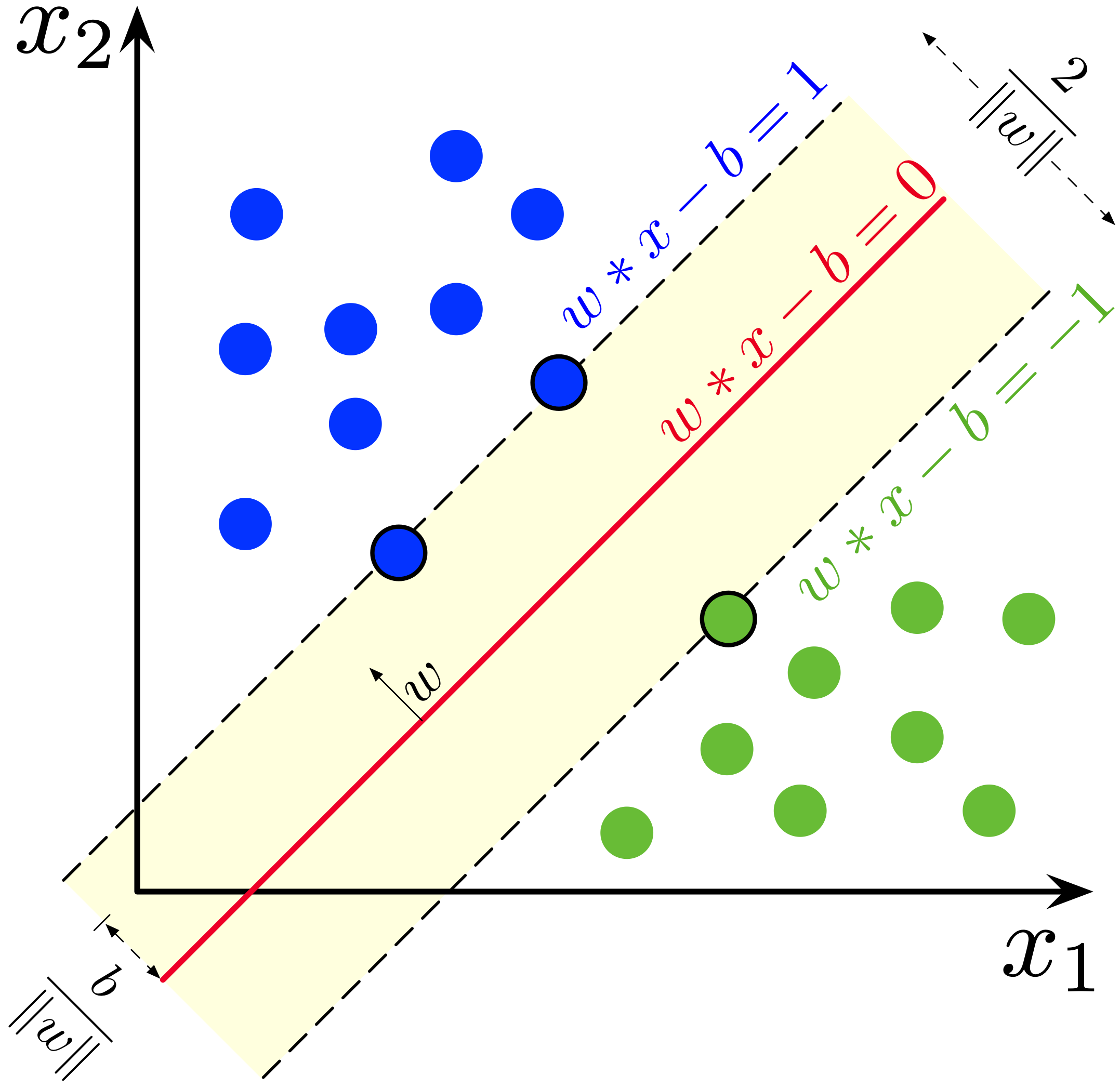
In the diagram above we separate the data with two parallel hyperplanes:
and
Since the distance between these hyperplanes is given by , we want to minimize in order to maximize the distance. We also have the additional constraints that
and
Multiplying both sides by combines both of these constraints into one. In summary, we get the following optimization problem:
Once we have solved for and , we get the classifier function .
If the data is not linearly separable, we use soft margins by making use of the hinge-loss function
Then the goal becomes to minimize
where is a parameter controlling the trade-off between increased margin size and ensuring the points lie on the correct sides of the margins. As an optimization problem:
For large enough , this will behave similar to hard margins.
Nonlinear SVM
We can create nonlinear classifiers by applying the “kernel trick” where we replace dot products with kernels. This allows an algorithm to fit the maximum-margin hyperplane to a transformed feature space.

Note that this can increase the generalization error, i.e., how accurately the model can predict outcome data for previously unseen data.
Some common kernels:
- Polynomial (homogeneous):
- Polynomial (inhomogeneous):
- Gaussian radial basis function: for . Often
- Sigmoid function: for some and
The kernel is related to the transform by the equation . We can represent in the transformed space by
Thus, for classification functions we can take the dot product with by using the kernel trick, i.e.,
The Kernel Trick
For nonlinear SVM we mapped our data set into a higher-dimensional space where we could linearly separate. The kernel trick is a method for a learning algorithm to learn a nonlinear function without explicitly mapping into the higher-dimensional space. We want our kernel which acts in the original space to act as an inner product in the transformed space . That is, given our transformation our kernel should satisfy
According Mercer’s theorem, such a function exists if the space has a suitable measure such that satisfies
for all square-integrable functions . If we choose cardinality as our measure, then this condition reduces to
for all finite sequences of points in and all real-valued coefficients .
Recall that the classification vector in the transformed space is given by
We can obtain the coefficients by the following optimization problem:
This problem can be solved with quadratic programming. We find an index such that and lies on the boundary of the margin in the transformed space. Then we solve
This leaves us with the classifier function
Scikit-Learn
The python package scikit-learn has support for SVMs. Documentation listing at https://scikit-learn.org/stable/modules/svm.html.
Scikit has three classes for binary and multi-class classifications: SVC, NuSVC, and LinearSVC. All three take in two arrays, which has shape number of samples-by-number of features and which is a vector with dimension number of samples.
from sklearn import svm
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = svm.SVC()
clf.fit(X, y)
# Predict a new value
clf.predict([[2., 2.]])The 2d-array represents the set of points in our data set. Where as, the vector is the classifications of each point . For example, in relation to paragonimiasis, could have a 2d-vector for each patient (e.g., weight + height) and would represent if the patient is ELISA positive/negative. Then we could separate that data using SVC.fit.
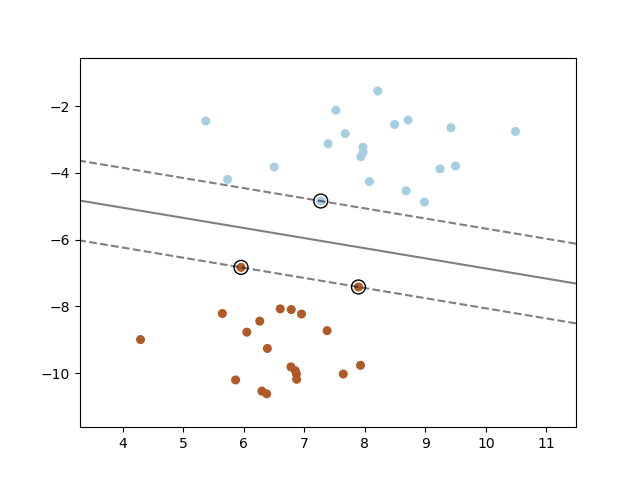
Below is some sample code:
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_blobs
from sklearn.inspection import DecisionBoundaryDisplay
# we create 40 separable points
X, y = make_blobs(n_samples=40, centers=2, random_state=6)
# fit the model, don't regularize for illustration purposes
clf = svm.SVC(kernel="linear", C=1000)
clf.fit(X, y)
plt.scatter(X[:, 0], X[:, 1], c=y, s=30, cmap=plt.cm.Paired)
# plot the decision function
ax = plt.gca()
DecisionBoundaryDisplay.from_estimator(
clf,
X,
plot_method="contour",
colors="k",
levels=[-1, 0, 1],
alpha=0.5,
linestyles=["--", "-", "--"],
ax=ax,
)
# plot support vectors
ax.scatter(
clf.support_vectors_[:, 0],
clf.support_vectors_[:, 1],
s=100,
linewidth=1,
facecolors="none",
edgecolors="k",
)
plt.show()which produces the following image: