The k-nearest neighbors algorithm (k-NN) is a non-parametric supervised learning method for classification and regression. In k-NN classification an object is assigned to the class most common among its nearest neighbors. The algorithm relies on a metric for classification. If data has varying scales or units then normalizing the training data can improve its accuracy.
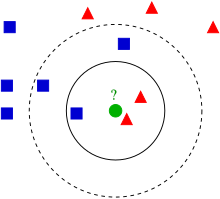
In the example above, if we use (three nearest neighbors) then the green circle will be classified with the triangles since there are more triangles than squares. However, if we use , then there are three neighboring squares and 2 neighboring triangles resulting in an assignment of square.
The choice of number of neighbors, , depends heavily on the data. In general, a larger suppresses the effects of noise but makes the classification boundaries less distinct.
The data should come in the form , where is the class label of . We also require a norm on . A common choice for continuous variables is Euclidean distance. For discrete variables a common choice is Hamming distance.
Skewed data can result in the more frequent class dominating the prediction of a new example. A way to overcome this problem is to weight the classification by taking into account the distance from the test point to each of its -nearest neighbors.