Authors: Ross Whitaker, Mahsa Mirzargar, and Robert Kirby
Original Paper: https://ieeexplore.ieee.org/document/6634129
Introduction
A crucial strategy within uncertainty quantification (UQ) is the construction of ensembles, i.e., collections of different simulations of the same physical process with varying parameters (think weather forecasting). In many cases these simulations provide level sets highlighting a desired feature.
How does one visualize an ensemble of data? One natural strategy is computing various statistics such as mean, variance/covariance, etc. However, these methods do not capture the underlying shape, position and variability of the level sets. The paper seeks to propose a new methodology of shape analysis with the following goals in mind:
- Informative about regions: visualization should apply to contours and convey statistical properties about their shapes, positions, etc.
- Qualitative interpretation: visualizations should provide high-level qualitative interpretations.
- Quantitative interpretation: visualizations should display well-defined statistical content.
- Statistical robustness: aggregate quantities in visualizations should not be sensitive to a small number of examples in the ensemble.
- Aggregation preserving shape: visualizations should display summary information but not hide details.
Band Depth Method and its Generalization to Contours
Order statistics such as median require an ordering on the data. For scalar data, this is easily obtained by simply sorting; however, for non-scalar data this ordering is less clear. One method is data depth, which provides a center-outward ordering of multivariate data. Data depth quantifies how central a particular sample is within a point cloud, with deeper samples considered more representative of the data.
Another method is known as band depth. Given an ensemble of functions , , (herein and are intervals in ) the band depth of each function is the probability that the function lies within the band defined by a random selection of functions from the distribution. For instance, a function lies in the band of randomly selected functions if it satisfies the following
I assume what we are saying here is that the image of lies in the band of if every point lies between the smallest and largest values. That would match the picture given in Figure 2a. As a set, we can visualize the band by
For a given , we define the band depth as the probability that a function falls into the band formed by an arbitrary set of other functions chosen at random from the ensemble, i.e.,
Band depth is more robust if one takes the sum of all smaller sets to form a band:
In practice we compute by a sample mean of the indicator function formed by evaluating over all appropriately sized subsets from the ensemble (excluding ). One should pick subset sizes so that all bands are sufficiently wide to contain and not too many examples have the same depth. For instance, for an ensemble containing 10 functions should test bands to compute .
The paper generalizes this notion of band depth and provides a modification that handles small sample sizes and high variability better. Let , where for some universal set , be an ensemble of sets. We say that
i.e., a set is in the band defined by other sets if it lies between the intersection and unions of the other sets. For example, consider the figure below:
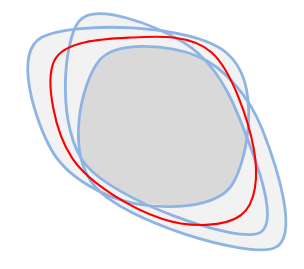
The set defined by the red contour lies in the contour band of the three blue contours as it lies between the intersection (gray) and the union (light gray).
The band depth is then defined by
Similar to , is computed by taking all appropriately sized subsets of .
The paper outlines an algorithm for applying to a set of level sets by considering the subsets in the plane enclosed by said level sets. Let be a set of fields. For a given , the algorithm for computing the of level sets with value is
- Compute the sets (as binary functions on a grid) for .
- For to
- Initialize
- For each subset of of size not containing
- Compute and (can do via min/max operations on the grid)
- If , then increment
- Normalize by dividing by the number of subsets -choose-.
- Sort the values of .
They call this application of set to level sets as contour band depth (). Note nothing in the above algorithm requires that we work in 2D domains.
This formulation may produce unsatisfactory results if the ensemble is relatively small and the contours vary significantly in shape. Thus, they relax the definition of subset:
i.e., is the empty set or the percentage of elements with is less than . Under this notion, the epsilon set band is then
Methods
The introduction of gives rise to a free parameter . The authors present a method in which can be tuned automatically to produce the most informative ordering of the data. If there are sets of against which to compare contours, then this gives an matrix where gives the percentage of mismatch for (where is a set of 2 contours from ) of the worst between union and intersections, i.e.,
If we sum along a column thresholding by and divide by , we get for that row/sample, i.e., if
then the sample mean of the band depth for a particular is given by
Aside:
Recall that given a one-dimensional random variable , a function is the probability density of if
Moreover, has cumulative distribution if
Notice that
i.e., by the fundamental theorem of calculus, .
TODO: Relearn measure theoretic probability.
Assume that a one-dimensional probability density, , has cumulative distribution , i.e., . Then (for ) a particular sample is in the band of two randomly chosen samples if one sample is less than and the other sample is greater where the probabilities are given by . That is,
Thus the expected value of the band depth is
As a result, the probability distribution does not matter. Hence we pick the that satisfies